
Yingyi Zhang
About Me
I am now a fourth-year PhD candidate at the joint program between Dalian University of Technology (DUT) and City University of Hong Kong (CityU). And I am jointly supervised by Prof. Xianneng Li (at DUT) and Prof. Xiangyu Zhao (at CityU). Before that, I graduated from DUT with a bachelor’s degree in Information Management and Information Systems in 2020. My interests lie in Personalized Recommender System, Personalized RAG, and Personalized LLM.
🔥 News
- [May. 2026] Our paper about Tool-Integrated Agents is accepted to ICML’26 as 🌟Spotlight, congrats to Dr. Junyi!
- [Apr. 2026] Our paper about Geographic LVLM is accepted to ACL’26 Main, congrats to Pengyue!
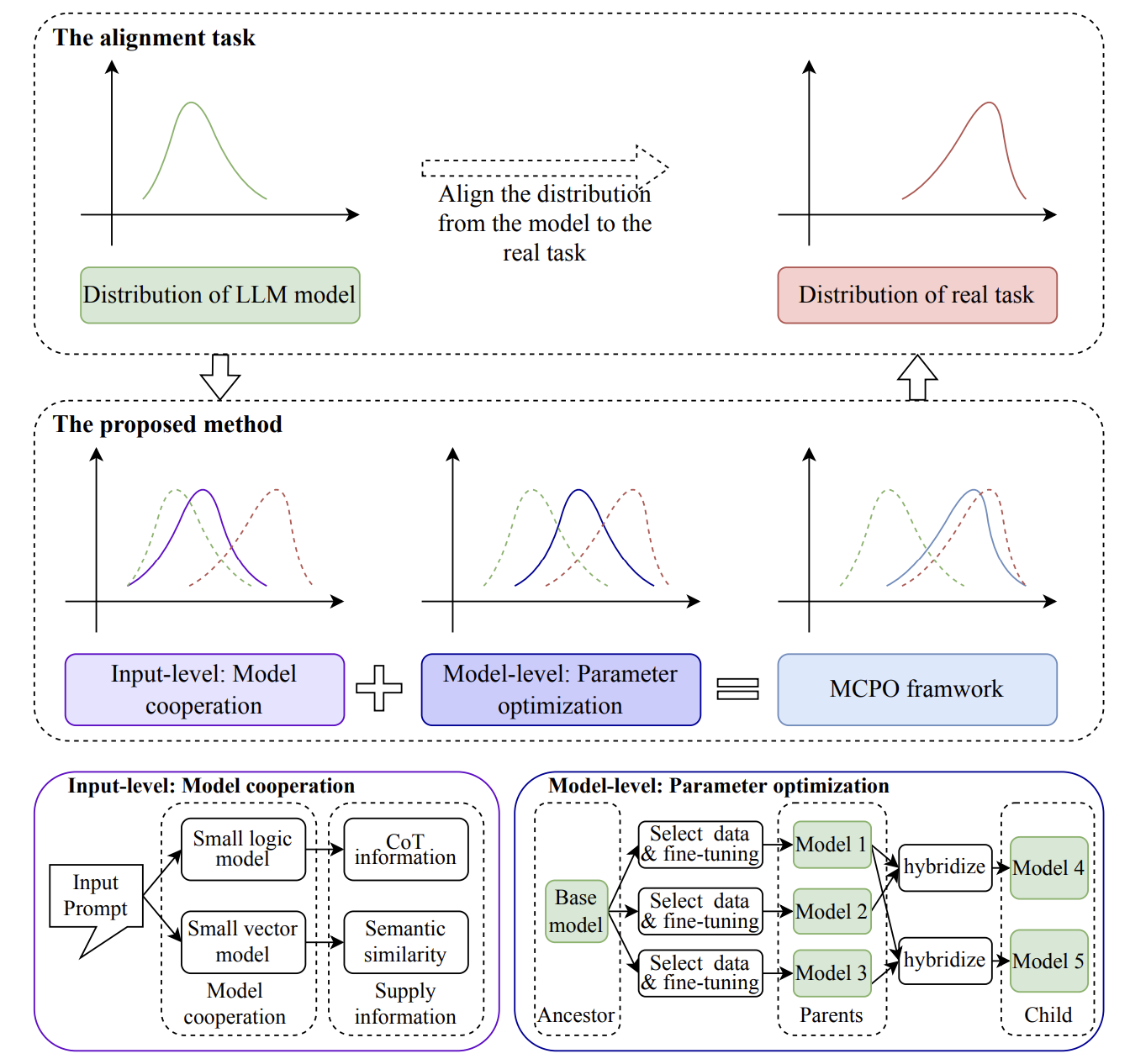
- [Apr. 2026] Our paper about Personalized LLM is accepted to ACL’26 Main, congrats to Xiaopeng!
- [Apr. 2026] Our paper about Agentic Search is accepted to ACL’26 Main, congrats to Sheng!
- [Apr. 2026] Our paper about Evolving Memory is accepted to ACL’26 Main, congrats to Derong!
- [Apr. 2026] Our Tutorial about Personalized RAG is accepted to SIGIR’26, congrats to Pengyue!
- [Apr. 2026] Our Resource about Personalized Deep Research is accepted to SIGIR’26, congrats to Xiaopeng!
- [Mar. 2026] I am selected as Volunteer for ICLR’26!
- [Feb. 2026] Our Tutorial about LLM Function Call is accepted to PAKDD’26, congrats to Prof. Maolin!
- [Feb. 2026] Our paper about Emergency Resource Management is accepted to ESWA, congrats to Yue Feng!
- [Jan. 2026] Our paper about Personalized Memory Retrieval is accepted to ICLR’26.
- [Jan. 2026] Our paper about Memory Management is accepted to ICLR’26, congrats to Derong!
- [Jan. 2026] Our paper about Search Agent Boundary is accepted to WWW’26, congrats to Wenlin!
- [Dec. 2025] Our Survey paper about LLM Function Call is accepted to CSUR, congrats to Prof. Maolin!
- [Dec. 2025] Our Survey paper about Personalized RAG is accepted to TOIS, congrats to Xiaopeng!
- [Nov. 2025] I am awarded the Student Scholarship prize at AAAI’26!
- [Nov. 2025] Our paper about Personalized Pre-Retrieval is accepted to AAAI’26 as 🌟ORAL!
- [Nov. 2025] Our paper about LLM4Rank is accepted to AAAI’26, congrats to Zhewei!
- [Sep. 2025] Our paper about Agentic RAG is accepted to Neurips’25, congrats to Wenlin!
- [Aug. 2025] Our paper about Debias in RecSys is accepted to CIKM’25, congrats to Yue Que!
- [May. 2025] Our paper about Cloud-Device Collaboration is accepted to KDD’25!
- [Feb. 2025] Our paper about User Intent Recognition is accepted to WWW’25, congrats to Zhipeng!
- [Feb. 2025] Our BMI@DLUT win the 🥉Bronze Medal at WWW compitition: Multimodal Dialogue System Intent Recognition Challenge!
- [Sep. 2024] I start the joint PhD. program bewteen DUT and CityU, joint supervised by Prof. Xianneng Li (at DUT) and Prof.Xiangyu Zhao (at CityU).
- [Aug. 2024] Our BMI@DLUT team awarded the 🥈Second Prize and Student Award in the KDD Cup 2024, User Behavior Alignment Track!
- [Nov. 2023] Our paper about Debias in RecSys is accepted to CAI’23, congrats to Yudi!
- [Sep. 2023] Our BMI@DLUT win the 🥉National Third Place at Supreme People’s Procuratorate National Procuratorate Big Data Legal Supervision!
- [Sep. 2023] I am awarded the Outstanding Graduate Student prize at DUT!
- [Jun. 2023] Our paper about Multi-Task in RecSys is accepted to RecSys’23, congrats to Zerong!
- [Jan. 2023] Our paper about Multi-Domain in RecSys is accepted to WWW’23!
- [Jan. 2023] Our paper about User Modelling in RecSys is accepted to Journal of Management Sciences in China, the Top 1 Chinese journal in Management and Science!
- [Sep. 2022] I start my PhD. career at DUT, supervised by Prof. Xianneng Li.
- [Sep. 2021] I start the research intern at Meituan in the search group.
🎖 Awards
-
2026Volunteer prize at ICLR'26 (~400 USD)
-
2026Student Scholarship prize at AAAI'26 (1,000 USD)
-
2025🥉Bronze medal at WWW compitition: Multimodal Dialogue System Intent Recognition Challenge (7,000 CNY)
-
2024Graduate Research Fund of the School of Economics and Management of Dalian University of Technology (50,000 CNY)
-
2024🥈Second price and Student Award: in KDD Cup 2024 Multi-task Online Shopping Challenge for LLMs at User Behavior Alignment Track (1,750 USD)
-
2023National Third Prize: Supreme People’s Procuratorate National Procuratorate Big Data Legal Supervision
-
2023Outstanding Graduate Student
-
2023Commended Paper: The eleventh CNAIS Annual Conference
-
2021Best Paper: The First Academic Conference on Data Intelligence and Management
📖 Education
-
 City University of Hong KongSep. 2024 - Now
City University of Hong KongSep. 2024 - Now -
 Dalian University of TechnologySep. 2022 - Now
Dalian University of TechnologySep. 2022 - Now -
Dalian University of TechnologySep. 2020 - Jul. 2022
-
Dalian University of TechnologySep. 2016 - Jul. 2020
📝 Publications
-
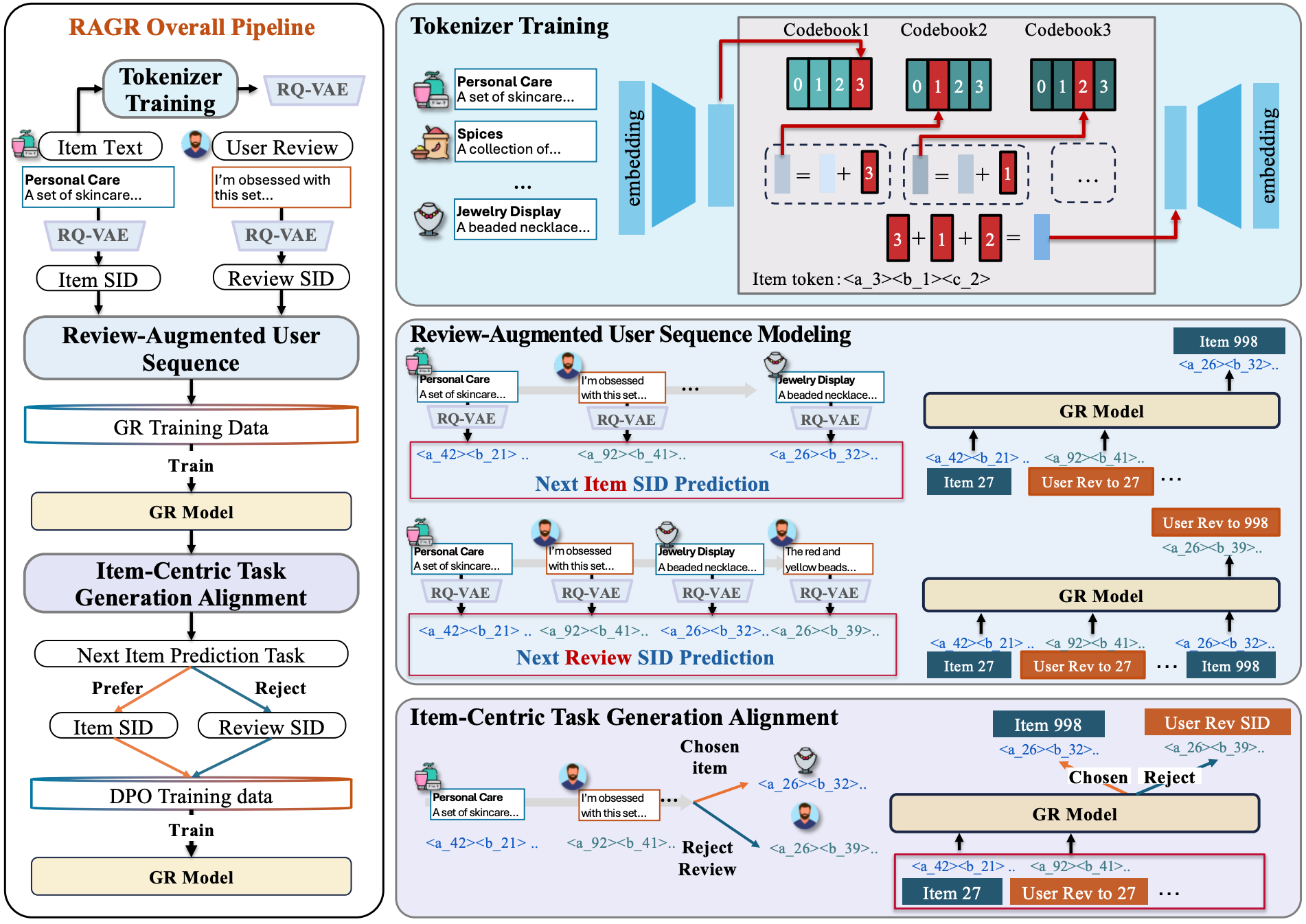 Arxiv
Arxiv
-
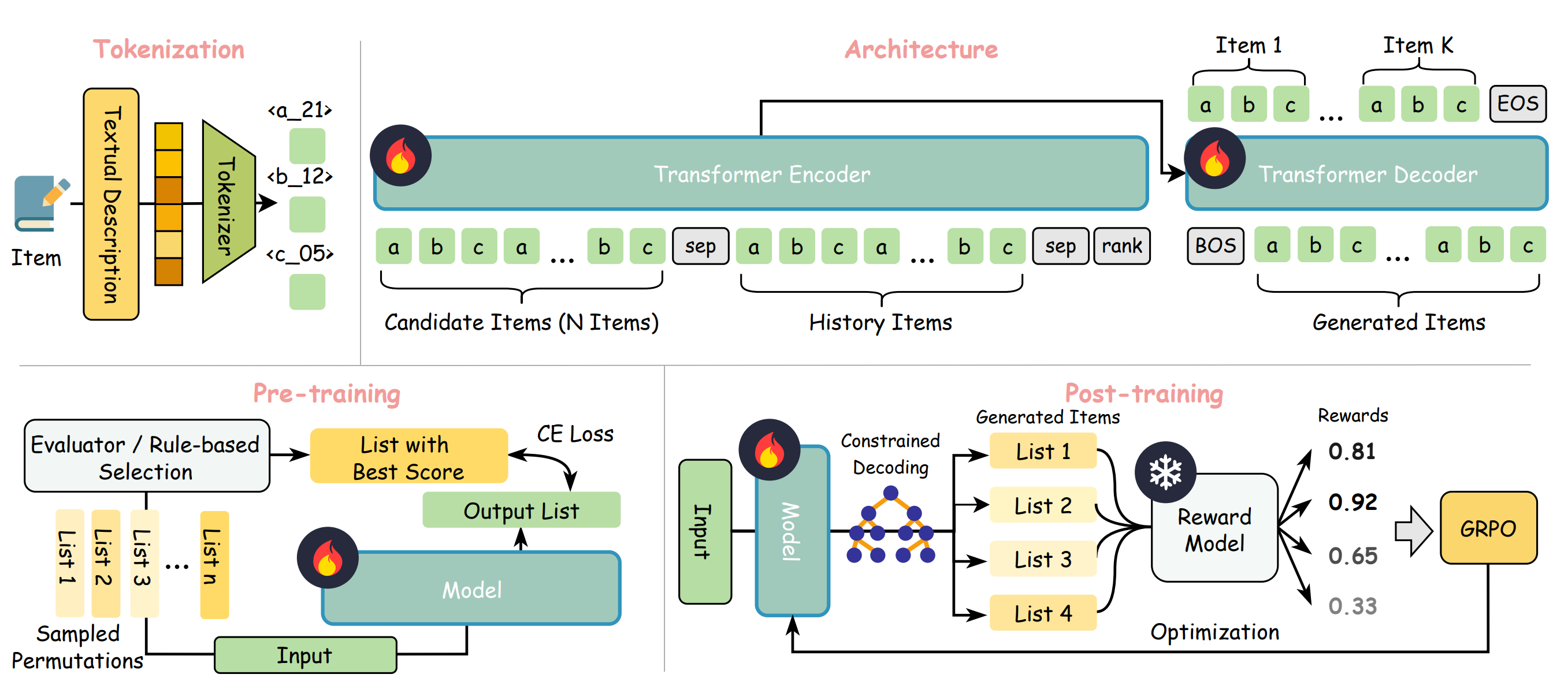 Arxiv
Arxiv
-
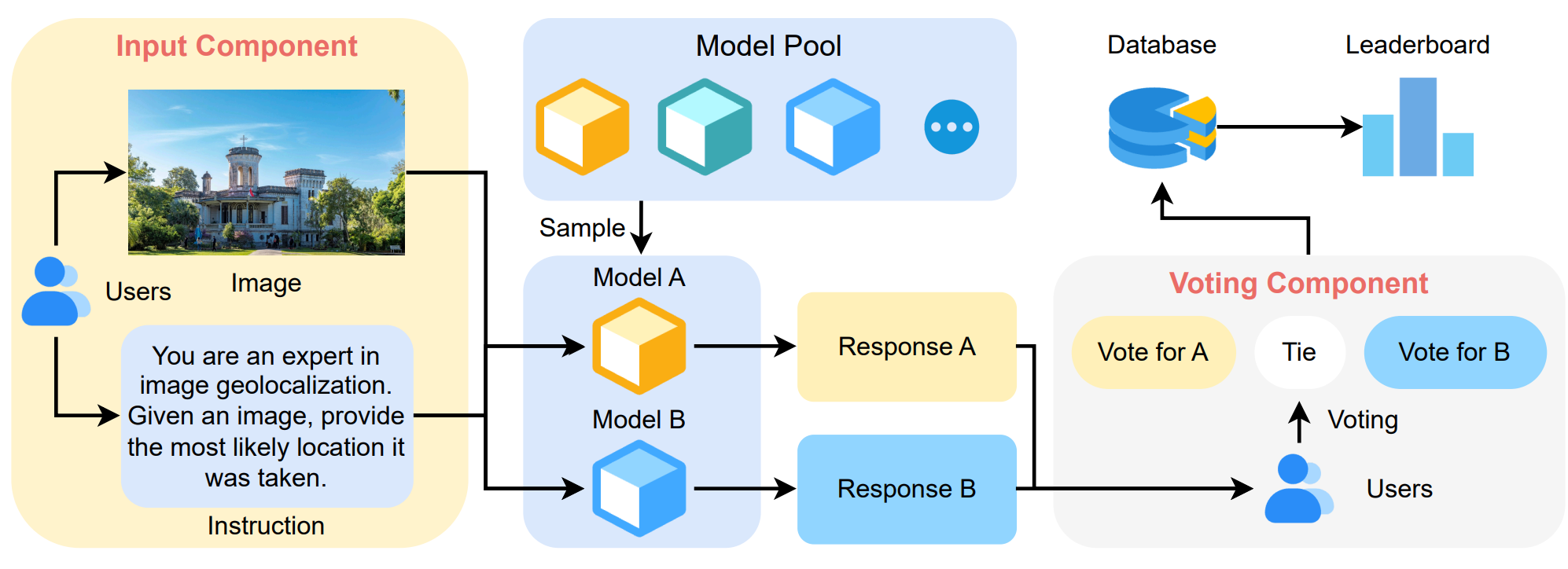 ACL'26-Main
The 64th Annual Meeting of the Association for Computational Linguistics (ACL'26), 2026.
ACL'26-Main
The 64th Annual Meeting of the Association for Computational Linguistics (ACL'26), 2026. -
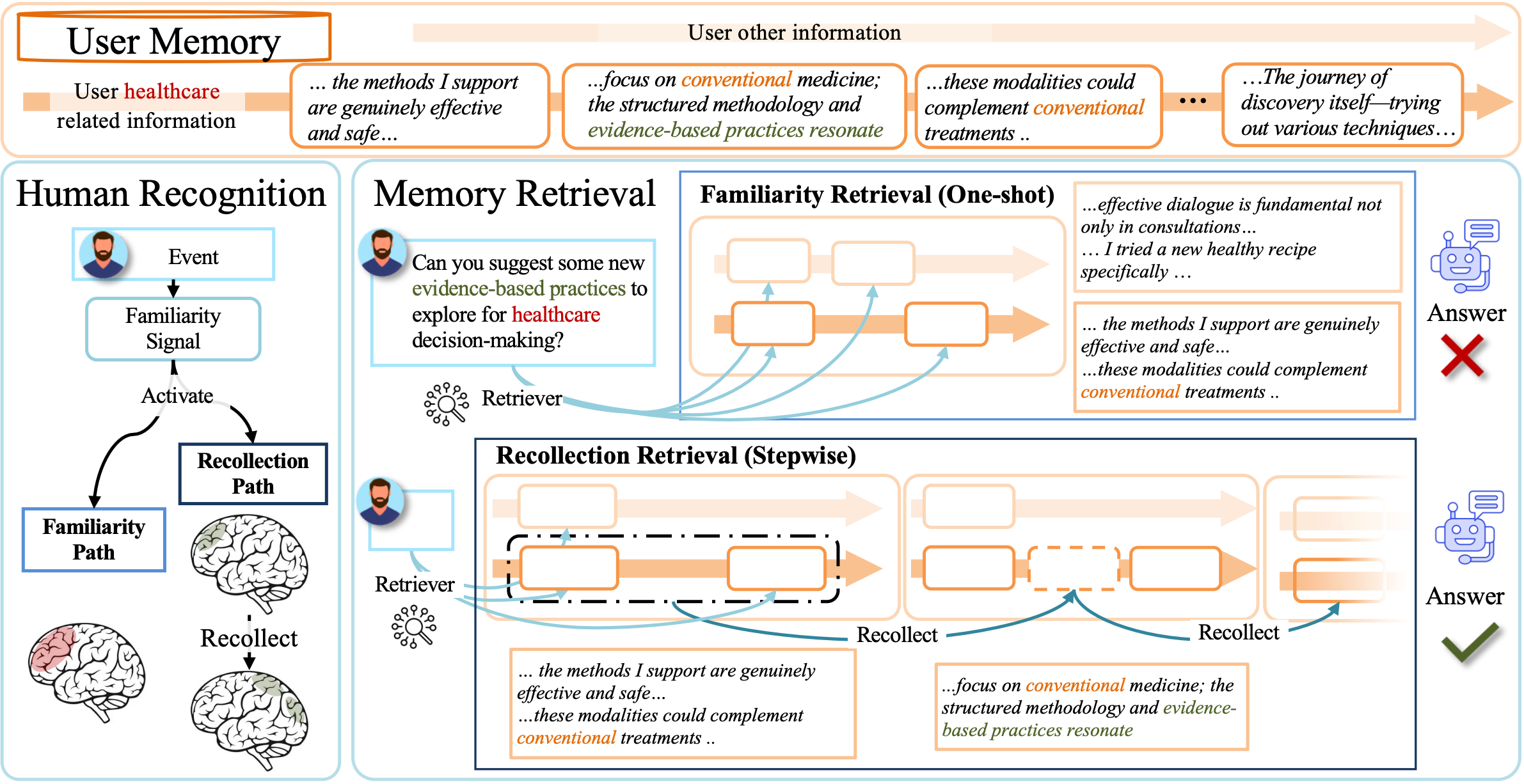 ICLR'26
The Fourteenth International Conference on Learning Representations (ICLR'26), 2026.
ICLR'26
The Fourteenth International Conference on Learning Representations (ICLR'26), 2026. -
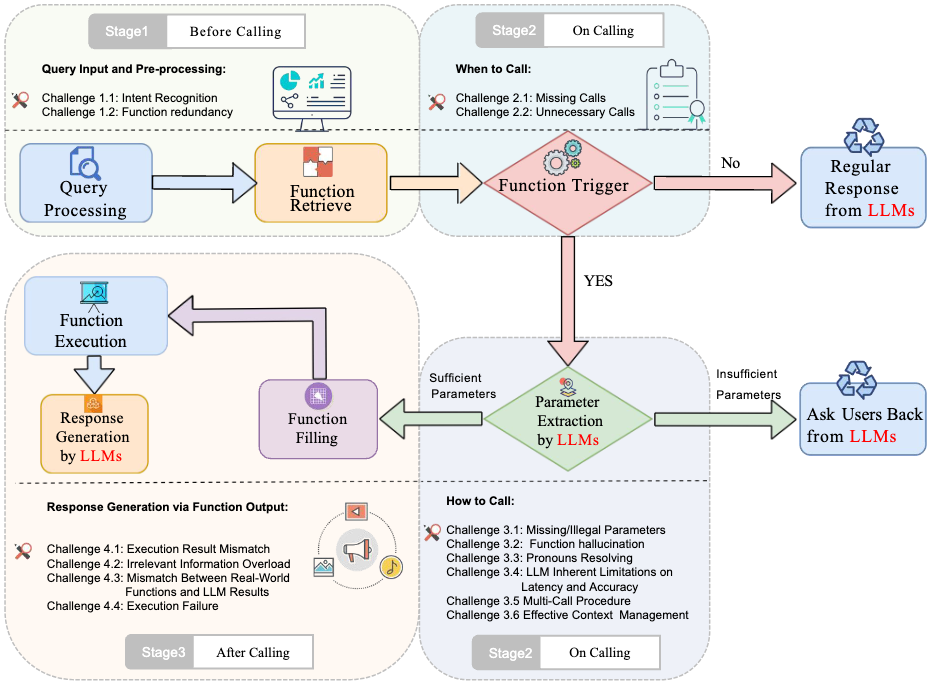 ACM CSUR
ACM Computing Surveys, 2026.PDF Top 1 Survey Journal in Computer Science, IF=26.3
ACM CSUR
ACM Computing Surveys, 2026.PDF Top 1 Survey Journal in Computer Science, IF=26.3 -
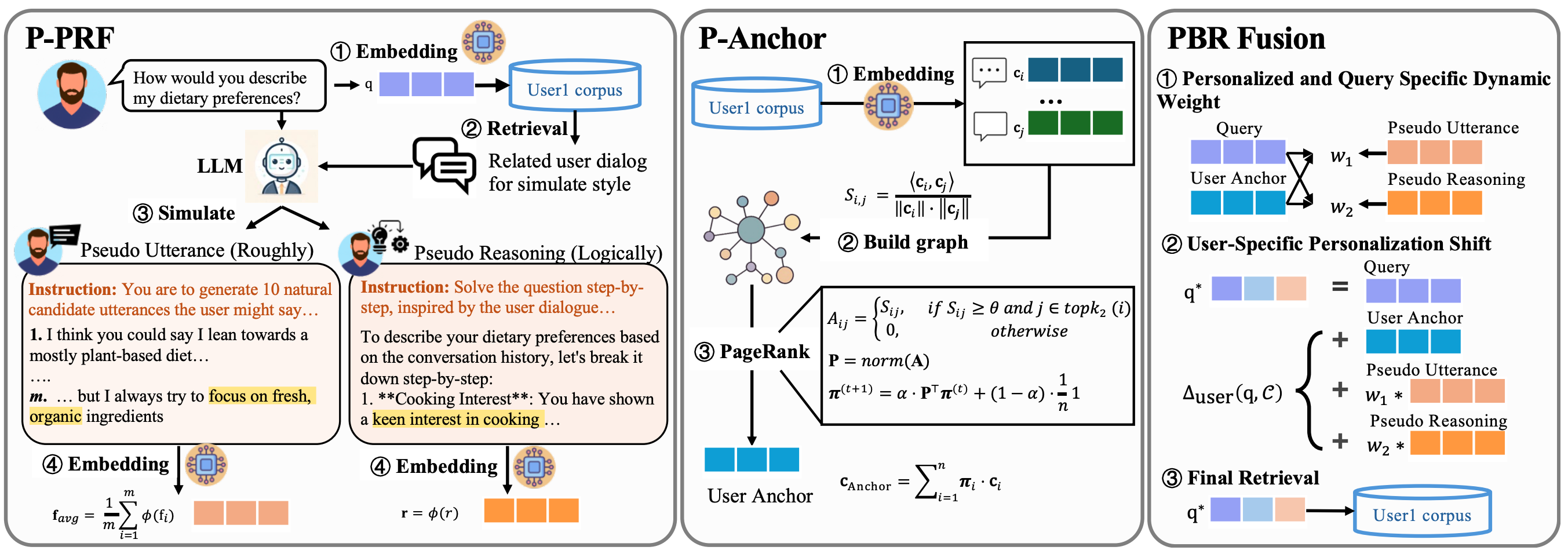 AAAI'26-Oral
The 40th Annual AAAI Conference on Artificial Intelligence (AAAI'26), 2026.
AAAI'26-Oral
The 40th Annual AAAI Conference on Artificial Intelligence (AAAI'26), 2026. -
 AAAI'26
The 40th Annual AAAI Conference on Artificial Intelligence (AAAI'26), 2026.
AAAI'26
The 40th Annual AAAI Conference on Artificial Intelligence (AAAI'26), 2026. -
 KDD'25
The 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD'25), 2025.
KDD'25
The 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD'25), 2025. -
 WWW'25
The ACM Web Conference (WWW'25 Compitition Track), 2025.PDF Project Page 🥉Bronze Medal
WWW'25
The ACM Web Conference (WWW'25 Compitition Track), 2025.PDF Project Page 🥉Bronze Medal -
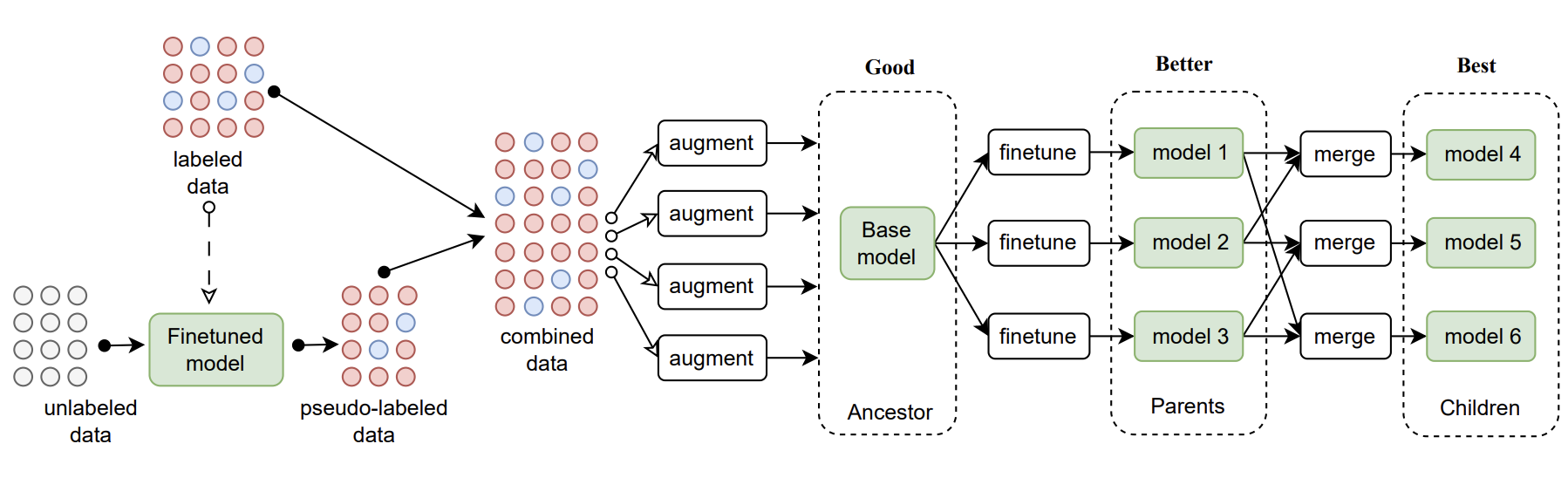
 Amazon KDD Cup
KDD Cup 2024 Workshop: A Multi-task Online Shopping Challenge for Large Language Models (Amazon KDD Cup), 2024.PDF Project Page 🥈Second Prize and Student Award
Amazon KDD Cup
KDD Cup 2024 Workshop: A Multi-task Online Shopping Challenge for Large Language Models (Amazon KDD Cup), 2024.PDF Project Page 🥈Second Prize and Student Award -
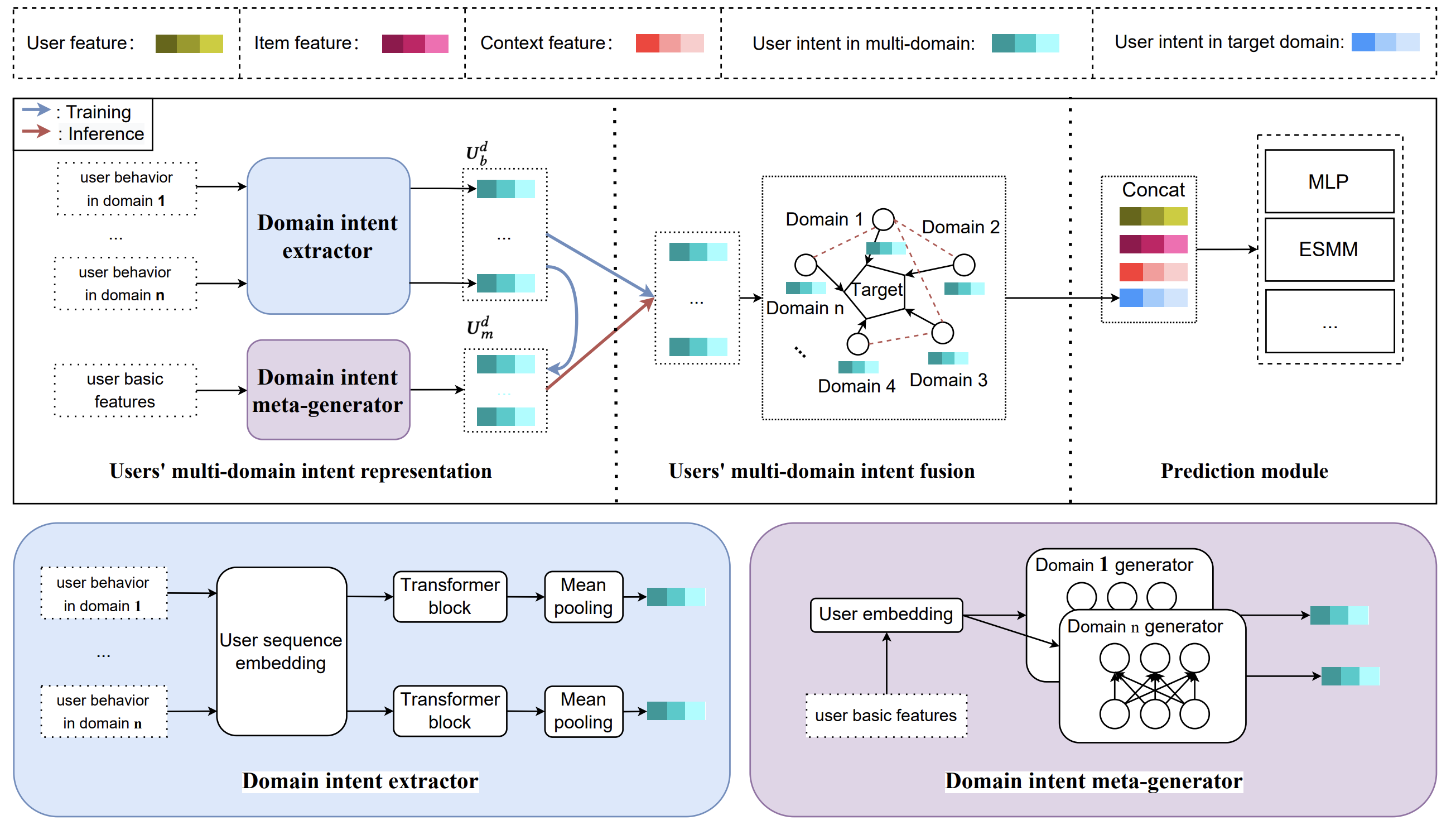 WWW’23 - industry truck
The ACM Web Conference (WWW'23 Industry Track), 2023.PDF An Online Deployed Systems in Meituan
WWW’23 - industry truck
The ACM Web Conference (WWW'23 Industry Track), 2023.PDF An Online Deployed Systems in Meituan -
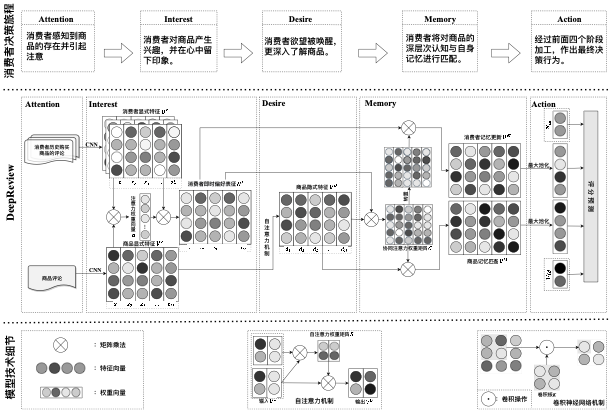 Journal of Management Sciences in China.PDF The Top 1 Chinese journal in Management and Science
Journal of Management Sciences in China.PDF The Top 1 Chinese journal in Management and Science -
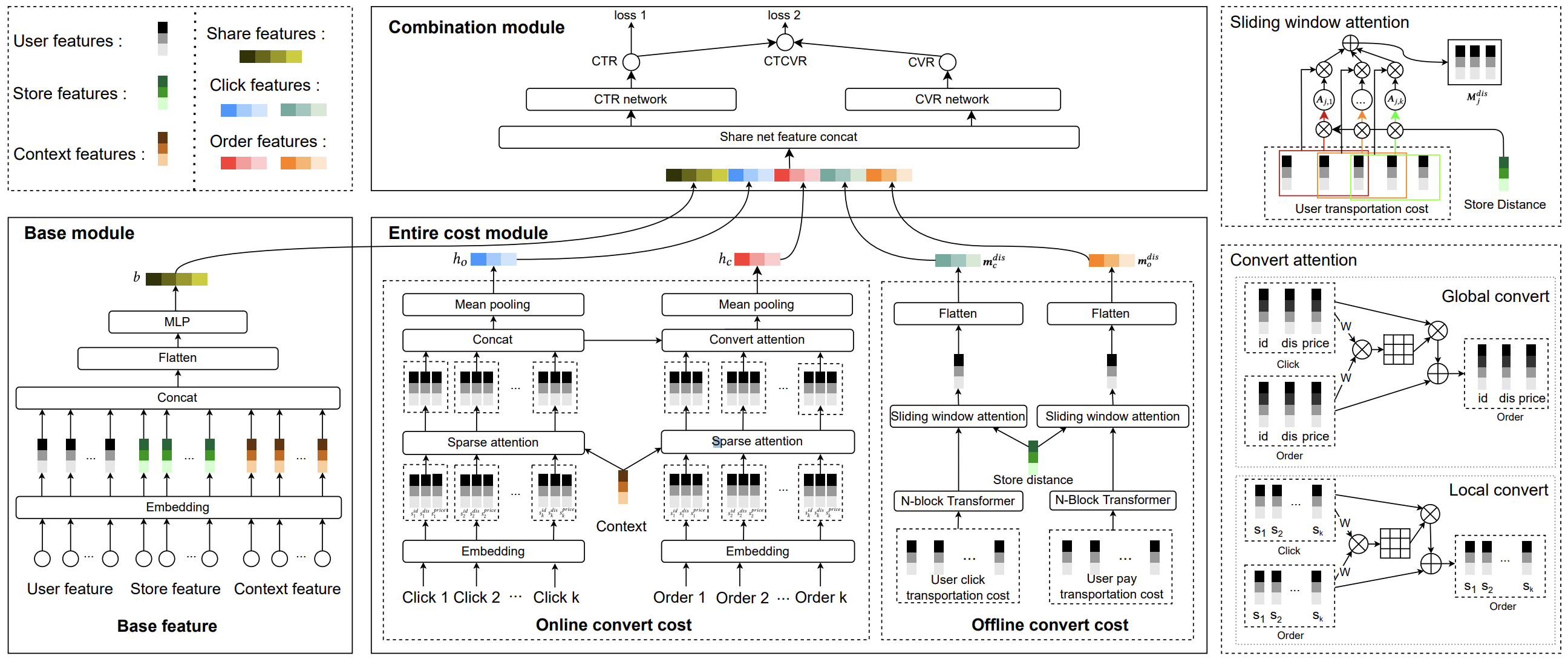 DL4SR@CIKM
Workshop on Deep Learning for Search and Recommendation, co-located with the 31st ACM International Conference on Information and Knowledge Management (DL4SR@CIKM), 2022.PDF An Online Deployed Systems in Meituan
DL4SR@CIKM
Workshop on Deep Learning for Search and Recommendation, co-located with the 31st ACM International Conference on Information and Knowledge Management (DL4SR@CIKM), 2022.PDF An Online Deployed Systems in Meituan
- Other Metioned Papers
- Junyi Li, Xiaowei Qian, Yingyi Zhang, Wenlin Zhang, Guojing Li, Sheng Zhang, Xiao Han, Yichao Wang and Xiangyu Zhao Towards Pareto-Optimal Tool-Integrated Agents with Pareto Ranking Policy Optimization. ICML’26 as Spotlight paper
- Xiaopeng Li, Yuanjin Zheng, Wanyu Wang, Wenlin Zhang, Pengyue Jia, Yingyi Zhang, Haiying He, Mengyang Ma, Yiqi Wang, Maolin Wang, Xuetao Wei and Xiangyu Zhao MTA:A Merge-then-Adapt Framework for Personalized Large Language Models. Accepted at ACL’26 Main
- Sheng Zhang, Junyi Li, Yingyi Zhang, Pengyue Jia, Yichao Wang, Xiaowei Qian, Wenlin Zhang, Maolin Wang, Yong Liu abd Xiangyu Zhao. MemSearch-o1: Empowering Large Language Models with Reasoning-Aligned Memory Growth in Agentic Search. Accepted at ACL’26 Main
- Derong Xu, Shuochen Liu, Pengfei Luo, Pengyue Jia, Yingyi Zhang, Yi Wen, Yimin Deng, Wenlin Zhang, Enhong Chen, Xiangyu Zhao and Tong Xu. Learning How and What to Memorize: Cognition-Inspired Two-Stage Optimization for Evolving Memory. Accepted at ACL’26 Main
- Pengyue Jia, Xiaopeng Li, Derong Xu, Yi Wen, Yingyi Zhang, Wenlin Zhang, Wanyu Wang, Yichao Wang, Yong Liu, Huifeng Guo and Ruiming Tang. Bridging Personalization and AI: From RAG to Agent. Accepted at SIGIR’26 Tutorial Track
- Xiaopeng Li, Wenlin Zhang, Yingyi Zhang, Pengyue Jia, Yejing Wang, Yichao Wang, Yong Liu, Huifeng Guo and Xiangyu Zhao. Personalized Deep Research: A User‑Centric Framework, Dataset, and Hybrid Evaluation for Knowledge Discovery. Accepted at SIGIR’26 Resource track
- Yue Feng, Yingyi Zhang, Ming Cong, Lili Rong. When coordinated response meets complexity in catastrophes: Unlocking cross-sectoral emergency resource sharing. Accepted at ESWA
- Derong Xu, Yi Wen, Pengyue Jia, Yingyi Zhang, Wenlin Zhang, Yichao Wang, Huifeng Guo, Ruiming Tang, Xiangyu Zhao, Enhong Chen, Tong Xu. From Single to Multi-Granularity: Toward Long-Term Memory Association and Selection of Conversational Agents. Accepted at ICLR’26
- Wenlin Zhang, Kuicai Dong, Junyi Li, Yingyi Zhang, Xiaopeng Li, Pengyue Jia, Yi Wen, Derong Xu, Maolin Wang, Yichao Wang, Yong Liu and Xiangyu Zhao. To Search or Not to Search: Aligning the Decision Boundary of Deep Search Agents via Causal Intervention. Accepted at WWW’26
- Xiaopeng Li, Pengyue Jia, Derong Xu, Yi Wen, Yingyi Zhang, Wenlin Zhang, Wanyu Wang, Yichao Wang, Zhaocheng Du, Xiangyang Li, Yong Liu, Huifeng Guo, Ruiming Tang, Xiangyu Zhao. A Survey of Personalization: From RAG to Agent. Accepted at TOIS
- Wenlin Zhang, Xiaopeng Li, Yingyi Zhang, Pengyue Jia, Yichao Wang, Huifeng Guo, Yong Liu, Xiangyu Zhao. Deep research: A survey of autonomous research agents. Preprint
- Wenlin Zhang, Xiangyang Li, Kuicai Dong, Yichao Wang, Pengyue Jia, Xiaopeng Li, Yingyi Zhang, Derong Xu, Zhaocheng Du, Huifeng Guo, Ruiming Tang, Xiangyu Zhao. Process vs. Outcome Reward: Which is Better for Agentic RAG Reinforcement Learning. Accepted at Neurips’25
- Yue Que, Yingyi Zhang, Xiangyu Zhao, Chen Ma. Causality-aware Graph Aggregation Weight Estimator for Popularity Debiasing in Top-K Recommendation. Accepted at CIKM’25
- Yudi Xiao, Yingyi Zhang, Xianneng Li. Modeling Variational Anchoring Effect for Recommender Systems. Accepted at CAI’23
- Zerong Lan, Yingyi Zhang, Xianneng Li. M3REC: A Meta-based Multi-scenario Multi-task Recommendation Framework. Accepted at RecSys’23
💻 Internships
- Oct. 2024 - Now: Research Intern at Huawei, Noah’s Ark Lab.
- Working on Personalized RAG and Recommendation with LLM.
- Sep. 2021 - Jul. 2022: Research Intern at Meituan, Search Group.
- Studied on Cross Business Domain Complementary and Fusion Methods from Perspective of Consumer Behavior Understanding.
✏️ Services
- Volunteer
- 2026: AAAI, ICLR
- Reviewer
- 2026: AAAI
Powered by Jekyll and Minimal Light theme.